
La sintesi vocale è quell’operazione che traduce fondamentalmente le informazioni scritte (testo scritto) in informazioni uditive utilizzando una voce generata dal computer. I programmi di sintesi vocale, in grado di convertire testo in parlato, sono ideali per l’apprendimento delle lingue straniere, per i non vedenti i cui contenuti sullo schermo possono essere letti ad alta voce, e per una serie di altre attività dove risulta più conveniente l’ascolto di un testo anzichè la lettura.
Alcuni degli esempi più importanti e popolari di sintetizzatori vocali sono Alexa, Cortana e Google Home. Di seguito vogliamo segnalare alcuni programmi Text To Speech, in grado di convertire testo in audio parlato, in modo totalmente gratuito.
#1. TexToSpeech
TexToSpeech è una piccola utility, che non richiede installazione, e che una volta avviato consente di trasformare qualsiasi testo selezionato in audio. Il suo funzionamento è davvero banale. Ecco i dettagli.
Passo 1. Scarica TexToSpeech sul tuo PC Windows
Ecco il link per il download:

Passo 2. Esegui TexToSpech
Dopo il download otterrai un file .zip. Apri questo file ed estrai dall’interno il file TexToSpeech.exe. Trascina questo file sul tuo desktop (o in qualsiasi altra cartella del tuo PC).

Dopo aver fatto click sull’icona di TexToSpeech, si aprirà una finestra del genere, che ti dirà che il programma è pronto per “leggere” ad alta voce il testo che selezionerai.

Passo 3. Seleziona testo e premi F8
Adesso seleziona il testo (da un qualsiasi documento come blocco note, file PDF, Word, Powerpoint, ecc…) e poi premi il pulsante F8. Dovrebbe partire in automatico il sintetizzatore vocale che leggerà quel testo selezionato.
Per ottimizzare la qualità dell’audio e il volume, fai click (col tasto destro del mouse) in basso a sinistra del desktop sull’icona di TexToSpeech come evidenziato nella figura seguente:
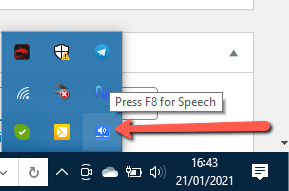
Facendo click col tasto destro del mouse appariranno due opzioni: “Settings” e “Exit”. Clicca su Settings per aprire la finestra seguente:

Da questa finestra potrai impostare il tasto da premere per riprodurre l’audio (di default è impostato F8). Potrai anche scegliere la voce (in base a quelle installate nel tuo PC Windows). Poi potrai anche decidere la velocità di lettura e il volume della voce riprodotta.
Tutto qui! Provalo subito, è gratis! Se non sei soddisfatto leggi qui di seguito altre possibili soluzioni (sia gratuite che a pagamento).
Altri Programmi di Sintesi Vocale (Gratis e a Pagamento)
A) Text–to-Speech
Text-to-Speech di Google consente agli sviluppatori di sintetizzare i suoni naturali in più di 100 voci.
Coinvolge principalmente la ricerca WaveNet di DeepMind e le reti neurali di Google per fornire output vocali.
Caratteristiche principali:
- Selezione della voce e della lingua: puoi usufruire di un’ampia varietà di oltre 220 voci e oltre 40 lingue.
- Accordatura del tono: gli utenti possono aumentare o diminuire il tono della voce selezionato fino a 20 semitoni in più o anche in meno rispetto all’impostazione predefinita.
- Flessibilità del formato audio: ottieni gli output desiderati in formati come mp3, Linear16 e Ogg Opus.
Prezzo:

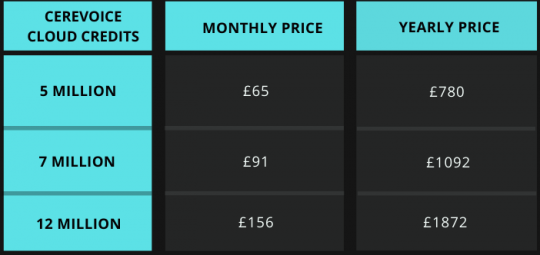
B) CereVoice
CereVoice è uno strumento di clonazione vocale online basato sul web sviluppato da CereProc. Gli utenti possono utilizzarlo dai propri computer senza la necessità di apparecchiature di supporto o ambienti di tipo studio. Gli utenti devono leggere lo script appositamente progettato.
I dati raccolti tramite questo script vengono ulteriormente utilizzati per creare una versione Windows SAPI5 TTS o MacOS della tua voce. È disponibile in inglese, spagnolo, francese, svedese, italiano e rumeno.
Caratteristiche principali:
- Capacità di uscita audio stereo e 3D sono disponibili per gli utenti.
- Integrazione: le funzioni di sintesi vocale funzionano bene con tutti i diversi tipi di applicazioni, siano esse mobili, web o basate su server.
- Distribuzione gratuita: non ti verrà addebitato alcun costo aggiuntivo per la distribuzione dell’audio generato tramite questo software
Prezzo:
C) eSpeak
eSpeak è un sintetizzatore vocale software open source. Sono disponibili più lingue agli utenti di dimensioni inferiori poiché questi strumenti utilizzano un metodo di sintesi formante. L’output vocale generato tramite eSpeak è chiaro e può essere utilizzato a velocità più elevate.
Caratteristiche principali:
- Output audio in formato WAV.
- Voci possono essere modificate e sono rese disponibili per gli utenti da eSpeak.
- Dimensioni compatte: i dati ei file di programma ammontano a soli 2 MB.
Prezzo: è un software open source, quindi gratuito al 100%.
D) Voicery
Voicery è un avanzato motore di sintesi vocale neurale. Agli utenti viene fornita una soluzione personalizzabile di sintesi vocale basata sulle interazioni fatte con loro. I requisiti aziendali dei modelli di sintesi vocale per gli utenti vengono debitamente selezionati mentre si lavora direttamente con il team di Voicery.
Se gli utenti desiderano distribuire le loro voci su qualsiasi piattaforma, Voicery consente loro di farlo registrando le loro voci attraverso letture di copioni, letture in studio ed elaborazione audio.
Caratteristiche principali:
- Tocco intelligenza artificiale e apprendimento: gli utenti possono aggiungere accento ed emozioni nelle loro voci con l’aiuto di tecnologie di intelligenza artificiale e apprendimento veloce.
- Distribuzioni: l’implementazione semplice di questo strumento può essere eseguita su cloud, in sede o anche offline.
- Regolazioni audio: il linguaggio di markup della sintesi vocale aiuta ad apportare modifiche come pause, formattazione audio, ecc.
Prezzo: il costo è di $ 0,001 per personaggio con vantaggi come l’accesso alla libreria vocale fino a 100 richieste al secondo. Per le aziende ci sono sconti per utilizzo in blocco, voci esclusive personalizzate e richieste illimitate.
E) Overdub
Overdub è ottimo per apportare brevi correzioni editoriali. Gli utenti possono mettere insieme alcuni audio segnaposto e i suoni reali possono sostituire gli stessi audio. Una volta che gli utenti hanno impostato una voce Overdub registrando minuti di audio, dovranno aprire un progetto Descript. Gli utenti selezioneranno quindi la voce Overdub dall’elenco delle etichette degli altoparlanti e digiteranno o incolleranno il testo. Durante la digitazione della descrizione verrà generato automaticamente l’audio nella tua voce. Se gli utenti hanno scritto il loro script in altri strumenti, possono copiarlo e incollarlo su Overdub e gli utenti saranno pronti a lavorare.
Caratteristiche:
- Facile da usare: l’integrazione di Overdub con Descript semplifica la creazione di audio come la digitazione.
- Condivisione: gli utenti possono condividere facilmente la loro voce Overdub con altre piattaforme per la generazione di audio.
- Si fonde perfettamente: se ci sono alcune modifiche da fare tra alcune frasi di registrazioni reali, Overdub è in grado di far corrispondere le caratteristiche tonali in una frase anche e anche nella registrazione.
Prezzo: $30 per utente al mese

GloboSoft è una software house italiana che progetta e sviluppa software per la gestione dei file multimediali, dispositivi mobili e per la comunicazione digitale su diverse piattaforme.
Da oltre 10 anni il team di GloboSoft aggiorna il blog Softstore.it focalizzandosi sulla recensione dei migliori software per PC e Mac in ambito video, audio, phone manager e recupero dati.